백업 및 재해 복구#
Mattermost 서버를 다양한 유형의 장애로부터 보호하는 옵션은 단순한 백업부터 정교한 재해 복구 배포 및 자동화까지 다양합니다.
백업#
Mattermost 서버의 상태는 여러 데이터 저장소에 포함되어 있으며, 시스템을 완전히 복구하려면 이러한 저장소를 개별적으로 백업하고 복원해야 합니다.
Mattermost 서버를 백업하려면:
데이터베이스 버전에 따라 표준 절차를 사용하여 Mattermost 데이터베이스를 백업하세요. PostgreSQL SQL Dump 백업 문서 가 온라인에서 제공됩니다. 페이지 상단의 탐색을 사용하여 PostgreSQL 버전을 선택하세요.
config/config.json에 저장된 서버 설정을 백업하세요. Mattermost에 SAML 구성을 사용하는 경우 SAML 인증서 파일이config디렉토리에 저장됩니다. 따라서 전체 디렉토리를 백업하는 것을 권장합니다.다음 옵션 중 하나를 사용하여 사용자가 저장한 파일을 백업하세요:
기본
./data디렉토리를 사용하여 로컬 스토리지를 사용하는 경우 이 디렉토리를 백업하세요.
config.json의Directory설정에 지정된 기본이 아닌 디렉토리를 사용하여 로컬 스토리지를 사용하는 경우 해당 위치의 파일을 백업하세요.파일을 S3에 저장하는 경우 일반적으로 백업 없이 현재 위치에 파일을 유지할 수 있습니다.
참고
깨끗한 백업을 만들려면 백업 중에 Mattermost를 중지해야 합니다. 그렇지 않으면 데이터베이스와 파일이 동기화되지 않을 수 있습니다.
백업에서 Mattermost 인스턴스를 복원하려면 데이터베이스, config.json 파일, 그리고 선택적으로 로컬에 저장된 사용자 파일을 백업했던 위치로 복원하세요.
재해 복구#
적절한 재해 복구 계획은 특정 위험을 완화하는 이점과 재해 복구 인프라 및 자동화 설정의 비용과 복잡성을 비교하여 평가합니다.
자동화된 백업#
Mattermost 서버의 백업을 자동화하면 특정 시점의 서버 상태 복사본을 제공하며, 향후 장애로 인해 데이터 손실이 발생할 경우 복원할 수 있습니다. 옵션은 다음과 같습니다:
Mattermost 서버를 주기적으로 백업하는 자동화로, 보호하려는 항목에 따라 위에 나열된 모든 구성 요소 또는 일부를 포함할 수 있습니다.
복구 시간을 단축하기 위해 백업에서 서버를 복원하거나 새 서버를 배포하는 자동화.
백업 자동화 실패로부터 보호하기 위해 백업이 성공적으로 생성되었는지 확인하는 자동화.
현장 시스템의 물리적 손실로부터 보호하기 위해 오프사이트에 백업을 저장.
백업을 사용하여 장애에서 복구하는 것은 일반적으로 수동 프로세스이며 다운타임이 발생합니다. 대안은 고가용성 배포를 사용하여 복구를 자동화하는 것입니다.
고가용성 배포#
중요 업무 운영에 Mattermost를 사용하는 Enterprise 고객은 지속적인 가용성과 운영 복원력을 보장해야 합니다. 데이터 센터 장애와 관련된 위험을 완화하고 예기치 않은 중단이 발생하더라도 사용자가 Mattermost에 원활하게 접근할 수 있도록 하기 위해서는 견고한 재해 복구 전략이 필수적입니다.
이 섹션에서는 재해 복구 모드에서 Mattermost를 설정하는 데 필요한 단계와 한 데이터 센터에서 다른 데이터 센터로 장애 조치하는 방법을 설명합니다.
하나의 데이터 센터에 설정#
첫 번째 단계로, 단일 데이터 센터에 Mattermost를 설정합니다. 매우 기본적인 수준에서는 다음과 같은 형태가 됩니다:
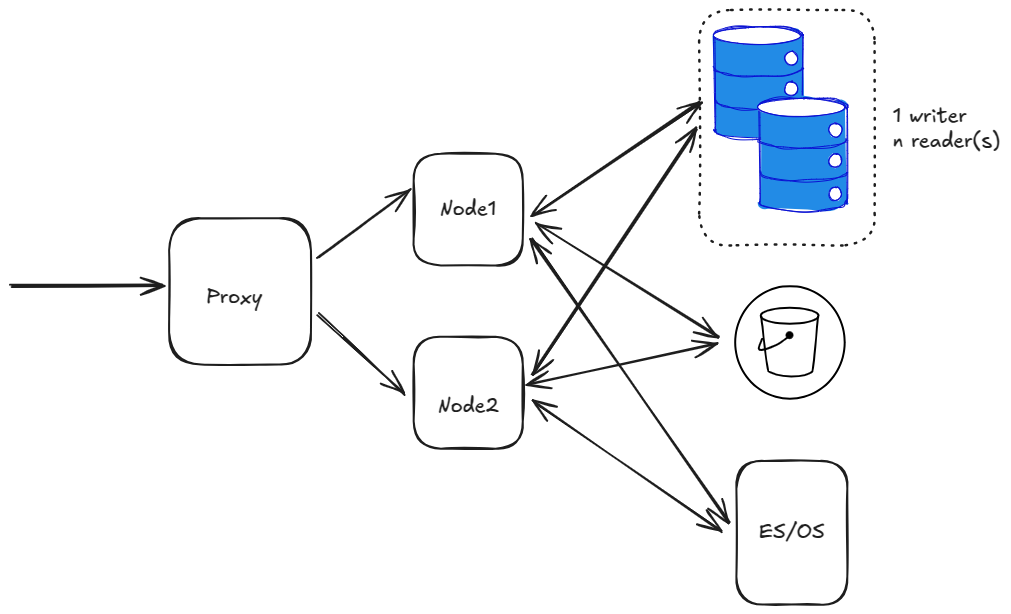
위 다이어그램은 단일 프록시가 2개의 노드로 트래픽을 전달하는 구조입니다. 또한 단일 writer + n개의 reader가 있는 데이터베이스와 AWS Opensearch 서비스를 사용하는 S3 버킷과 ES/OS가 있습니다.
이 단계에서는 LDAP/SAML, SMTP 등의 다른 세부 사항은 무시합니다.
팁
다음 아키텍처는 전체 리전이 다운될 때 구현됩니다. 단일 서버/서비스가 다운되는 경우는 다루지 않습니다. 예를 들어:
단일 앱 노드가 다운되면 모범 사례를 따라 새 노드를 프로비저닝합니다.
데이터베이스 복제본 노드가 다운되면 AWS 콘솔에서 새 복제본을 생성합니다. 또는 자동으로 수행하도록 정책을 설정합니다.
데이터베이스 복제#
다음 작업에는 글로벌 AWS 클러스터 생성이 포함됩니다.
AWS 콘솔에서 RDS 인스턴스를 선택하고 Actions 메뉴를 확장하여 Add AWS Region 을 선택합니다.
보조 리전을 선택하고 다른 세부 정보를 입력합니다.
경고
보조에서 기본으로 쓰기 작업을 전달하는 데 도움이 되도록 보조 클러스터에서 Enable write forwarding 옵션을 선택합니다. 자세한 내용은 AmazonRDS write forwarding 문서를 참조하세요.
또한 PostgreSQL 버전을 확인하고 write forwarding 을 허용하는지 확인하세요. 모든 PostgreSQL 버전이 이를 허용하지는 않습니다. 자세한 내용은 Amazon RDS write forwarding region and version availability 문서를 참조하세요.
이제 기본 클러스터가 us-west-1 에 있고 보조 클러스터가 us-east-1 에 있는 글로벌 클러스터가 있어야 합니다:
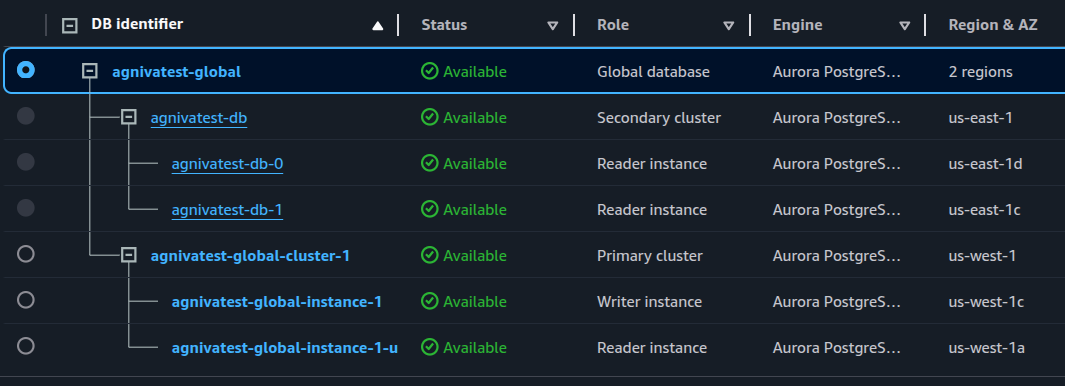
S3 버킷 복제#
보조 리전에 새 S3 버킷을 생성합니다.
원래 버킷으로 돌아가서 Properties 탭으로 이동하고 Bucket versioning 을 활성화합니다.
Management 탭으로 이동하여 Replication Rules 로 스크롤한 다음 새 복제 규칙을 생성합니다.
규칙에서 소스 버킷을 선택한 다음 버킷의 모든 항목을 복제하기 위해 Apply to all objects in the bucket 을 선택합니다.
대상 버킷을 선택합니다.
IAM 역할의 경우 Create new role 을 선택합니다.
경고
복제본과 소스 버킷이 서로 동기화되도록 버킷에 대해 Replica modification sync 옵션을 선택합니다.
Save 를 선택합니다.
기존 객체를 보조 버킷으로 복제하는 작업을 시작할지 묻는 메시지가 표시되면 Yes 를 선택합니다.
보조 버킷에서도 동일한 단계를 수행합니다.
이제 이러한 S3 복제본과 소스 버킷 간에 양방향 복제가 작동합니다.
ES/OS 스토리지 복제#
ES/OS 스토리지를 복제하려면 다음 요구사항을 갖춘 AWS Opensearch용 CCR(크로스 클러스터 복제)을 설정하세요:
Elasticsearch 7.10 또는 OpenSearch 2.x
세분화된 액세스 제어 활성화
노드 간 암호화 활성화
팁
세분화된 액세스 제어가 활성화된 최신 OpenSearch 버전만 있으면 됩니다. 세분화된 액세스 제어를 활성화하면 노드 간 암호화가 자동으로 활성화됩니다.
OS 도메인의 Security Configuration 탭에서 설정된 OS 클러스터에 대한 IAM 정책에
CrossClusterGet권한을 추가해야 합니다. AWS 권장사항에 따라 다음을 추천하지만, 필요에 따라 조정하셔도 됩니다:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": "es:ESHttp*", "Resource": "arn:aws:es:<region>:<acc_num>:domain/<domain_name>/*" }, { "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": "es:ESCrossClusterGet", "Resource": "arn:aws:es:<region>:<acc_num>:domain/<domain_name>" } ] }
요약하면:
OpenSearch 2.x를 사용하세요.
세분화된 액세스 제어를 활성화하세요.
마스터 사용자를 생성하고 서버 자격 증명을 기록하세요.
위와 같이 IAM 정책을 설정하세요.
경고
마스터 사용자를 생성한 후에는 Mattermost 애플리케이션 노드에서 OS에 대한 IP 기반 액세스가 작동하지 않을 수 있습니다. config.json 의 ElasticSearchSettings 섹션을 업데이트하여 서버 username 와 password 를 업데이트해야 할 수 있습니다.
보조 리전에 새 OS 클러스터를 생성하세요. 이 클러스터에 대해 동일한 단계를 다시 수행하세요.
경고
이 단계에서 기본 리전의 모든 인덱스에 데이터가 채워져 있는지 확인하세요. 아직 실행하지 않았다면 벌크 인덱스를 실행하세요.
기본 리전에서 보조 리전으로의 복제를 시작하세요.
먼저 보조 리전에서 기본 리전으로의 연결을 생성하세요. OS의 복제는 “pull” 모델로 작동하므로 보조 사이트가 기본 사이트에서 데이터를 가져옵니다.
Amazon OpenSearch Service 콘솔에서 보조 도메인을 선택하고 Connections 탭으로 이동한 다음 Request 를 선택하세요.
Connection alias 에 연결 이름을 입력하세요.
connect to a domain in another AWS account or region 을 선택하고 기본 도메인의 ARN 을 입력하세요.
기본 도메인에 권한 요청을 보내려면 Request 를 선택하세요.
기본 도메인을 열고 Connections 탭에서 들어오는 요청을 확인하고 수락하세요.
이제 인덱스에 대한 복제 규칙을 설정하세요.
일일 명명 체계와 월간 집계로 인해
posts*인덱스에 대한 자동 팔로우 규칙을 설정하려면 보조 리전의 앱 노드에 SSH로 접속하세요.다른 인덱스의 경우 각각을 복제하세요.
*를 사용하여 모든 것을 복제하는 규칙을 설정할 수도 있지만, 이는 원하지 않는 숨겨진 인덱스와 시스템 인덱스도 포함됩니다.
posts*인덱스에 대한 자동 팔로우를 설정하세요:curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/_autofollow?pretty' -d ' { "leader_alias" : "<LEADER_ALIAS>", "name": "autofollow-rule", "pattern": "posts*", "use_roles":{ "leader_cluster_role": "all_access", "follower_cluster_role": "all_access" } }'
자동 팔로우 규칙의 상태를 확인하세요:
curl -H 'Content-Type: application/json' -u 'username/password' 'https://<>/_plugins/_replication/autofollow_stats?pretty' { "num_success_start_replication" : 2, "num_failed_start_replication" : 0, "num_failed_leader_calls" : 0, "failed_indices" : [ ], "autofollow_stats" : [ { "name" : "autofollow-rule", "pattern" : "posts*", "num_success_start_replication" : 2, "num_failed_start_replication" : 0, "num_failed_leader_calls" : 0, "failed_indices" : [ ], "last_execution_time" : 1737699113927 } ] }
다음으로 다른 인덱스에 대한 복제를 설정하세요:
curl -XPUT -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/channels/_start?pretty' -d ' { "leader_alias": "<LEADER_ALIAS>", "leader_index": "channels", "use_roles":{ "leader_cluster_role": "all_access", "follower_cluster_role": "all_access" } }' curl -XPUT -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/users/_start?pretty' -d ' { "leader_alias": "<LEADER_ALIAS>", "leader_index": "users", "use_roles":{ "leader_cluster_role": "all_access", "follower_cluster_role": "all_access" } }' curl -XPUT -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/files/_start?pretty' -d ' { "leader_alias": "<LEADER_ALIAS>", "leader_index": "files", "use_roles":{ "leader_cluster_role": "all_access", "follower_cluster_role": "all_access" } }'
복제 규칙의 상태를 확인하세요:
curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/channels/_status?pretty' curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/files/_status?pretty' curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/users/_status?pretty' curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/posts_<DATE>/_status?pretty' curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/posts_<DATE>/_status?pretty' Sample output: { "status" : "SYNCING", "reason" : "User initiated", "leader_alias" : "<LEADER_ALIAS>", "leader_index" : "<INDEX>", "follower_index" : "<INDEX>", "syncing_details" : { "leader_checkpoint" : 16, "follower_checkpoint" : 16, "seq_no" : 17 } }
인덱스를 확인하세요. 보조 도메인에서 기본 도메인의 모든 인덱스를 볼 수 있어야 합니다:
curl -s -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_cat/indices?pretty'
작업 서버 복제#
작업 스케줄러가 보조 리전에서 계속 실행되면 작업을 가져와 실행하기 시작합니다. 따라서 보조 리전의 모든 노드에서 JobSettings.RunScheduler 를 false 로 설정하세요. 장애 조치가 발생하면 새 기본 리전에서 이를 활성화하고 새 보조 리전에서는 비활성화해야 합니다.
보조 리전 테스트#
위 단계가 완료되면 완전히 작동하는 보조 리전이 생성됩니다. 기본 리전과 동일한 노드 및 프록시 서버 설정을 복제할 수 있습니다. 보조 리전의 앱 노드는 Mattermost가 쓰기 전달에서 허용되지 않는 DDL 문을 실행하려고 하기 때문에 처음에는 시작할 수 없습니다. 따라서 연결을 시도하는 루프에 걸리게 됩니다. 리전 장애 조치가 발생하면 작동하기 시작합니다. 기본 리전은 여전히 읽을 수 있으며 모든 주기적 쓰기는 보조(이제 기본) 리전으로 전달됩니다.
경고
2개의 클러스터에서 동일한 데이터베이스를 사용하려면 두 리전의 서로 다른 클러스터에 대해 별도의 ClusterNames 가 있는지 확인하세요.
RDS를 보조 리전으로 장애 조치#
장애 조치를 수행하려면 RDS 글로벌 클러스터로 이동하여 작업 아래에서 전환 또는 글로벌 데이터베이스 장애 조치 를 선택한 다음 데이터 손실 없이 전환하려면 전환 을 선택하세요(완료하는 데 더 많은 시간이 소요됨). 또는 데이터 손실을 감수하고 더 빠른 장애 조치를 위해 장애 조치 를 선택할 수 있습니다. 전체 리전이 어차피 사용할 수 없는 경우 장애 조치 는 전환 보다 나쁘지 않습니다.
이 작업이 완료되면 연결을 시도하다가 멈춰있던 앱 노드가 진행되어 모든 것이 작동해야 합니다. 읽기/쓰기, 이미지 업로드 및 모든 것이 복제되어야 합니다. Opensearch 데이터를 제외한 모든 것이요.
ES/OS를 보조 리전으로 장애 조치#
ES/OS는 단일 인덱스에 대한 다중 작성자를 허용하지 않습니다. 한 번에 하나의 인덱스에만 쓸 수 있습니다. 따라서 복제 방향을 반대로 하고 보조에서 기본으로 복제를 시작하기 위해 몇 가지 수동 단계를 수행해야 합니다.
간단히 설명하자면, site1 이 기본이고 site2 가 보조라고 가정해 보겠습니다. 따라서 site1 의 OS는 리더 도메인이고 site2 는 팔로워입니다. 팔로워는 리더에서 데이터를 가져옵니다. site2 가 리더가 되고 site1 이 팔로워가 되는 방향으로 전환하려면.
AWS 콘솔에서
site1→site 2규칙을 제거하세요. 이렇게 하면 복제가 자동으로 일시 중지되지만site2의 인덱스는 여전히 읽기 전용입니다. 해당 복제 규칙을 제거하세요.자동 팔로우 규칙 제거:
curl -XDELETE -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/_autofollow?pretty' -d ' { "leader_alias" : "<LEADER_ALIAS>", "name": "autofollow-rule" }'
앞서 언급한 대로 자동 팔로우 규칙의 상태를 확인하세요.
복제 규칙 제거:
curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/channels/_stop?pretty' -d '{}' curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/files/_stop?pretty' -d '{}' curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/users/_stop?pretty' -d '{}'
앞서 언급한 대로 복제 규칙의 상태를 확인하세요.
이제 인덱스가 쓰기 가능해집니다
AWS 콘솔에서
site2→site1규칙을 추가하세요.site1에서 모든 인덱스를 팔로워로 만드세요. 먼저 모든 인덱스를 삭제해야 합니다:
curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/posts*?pretty' curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/channels?pretty' curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/files?pretty' curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/users?pretty'
인덱스 새로고침:
curl -XPOST -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_refresh?pretty'
모든 것이 삭제되었는지 확인하세요:
curl -s -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_cat/indices?pretty'
자동 팔로우 규칙과 복제 규칙을 추가하세요. 이전과 동일한 단계를 따르세요.
복제가 시작되었고 인덱스를 사용할 수 있는지 확인하기 위해 인덱스를 다시 나열하세요.
S3 버킷은 양방향으로 자동 복제됩니다#
S3 버킷이 양방향으로 자동 복제되도록 하기 위해 수행해야 할 작업은 없습니다.
엔드 투 엔드 테스트#
장애 조치가 발생하고 ES/OS 복제 방향이 전환되면 새 사이트를 정상적으로 사용할 수 있습니다.
이것이 최종 아키텍처가 됩니다:
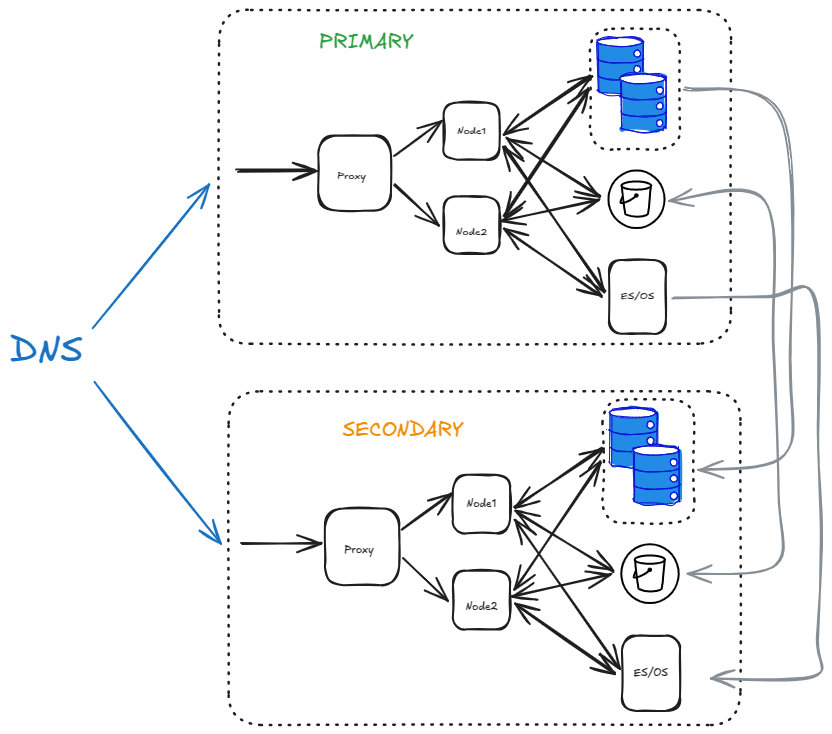
장애 조치 중에 DNS를 사용하여 PRIMARY에서 SECONDARY로 쉽게 전환할 수 있습니다.
팁
DNS를 전환했더라도 Websockets는 여전히 이전 데이터 센터를 가리킵니다. 이러한 연결을 새 데이터 센터로 이동하려면 각 앱 노드를 점진적으로 롤오버해야 합니다. 모든 노드가 다운된 경우에는 조치가 필요하지 않으며 클라이언트가 자동으로 새 데이터 센터에 다시 연결됩니다.
S3 버킷은 양방향으로 복제되는 반면, 데이터베이스와 ES/OS는 단방향으로 복제됩니다.
Single Sign-On 장애에서의 장애 조치#
Mattermost Enterprise Edition에서 Single Sign-on을 사용할 때 SSO 제공업체의 장애로 인해 Mattermost 인스턴스에 부분적인 장애가 발생할 수 있습니다.
SSO 장애 중에 어떤 일이 발생하나요?
대부분의 사용자는 여전히 로그인할 수 있습니다. 기본적으로 사용자가 Mattermost에 로그인하면 30일 동안 유효한 세션 토큰을 받습니다(기간은 System Console에서 구성할 수 있음). SSO 장애 중에는 유효한 세션 토큰이 있는 사용자가 중단 없이 Mattermost를 계속 사용할 수 있습니다.
일부 사용자는 로그인할 수 없습니다. SSO 장애 중에는 사용자가 로그인할 수 없는 두 가지 상황이 있습니다:
장애 중에 세션 토큰이 만료된 사용자.
새 기기에 로그인하려는 사용자.
각 경우에 사용자는 SSO 제공업체에 접근할 수 없고 로그인할 수 없습니다. 이 경우 다음과 같은 잠재적인 완화 방법이 있습니다:
SSO 제공업체를 고가용성으로 구성#
자체 호스팅 Single Sign-on 제공업체를 사용하는 경우, 계획되지 않은 장애로부터 시스템을 보호하는 고가용성 구성 에 사용할 수 있는 여러 옵션이 있습니다.
SaaS 기반 인증 제공업체의 경우, 서비스 가동 시간에 대한 의존성이 여전히 있지만 데이터를 가져오는 소스 시스템에 중복성을 설정할 수 있습니다. 예를 들어, OneLogin SaaS 기반 인증 서비스를 사용하면 고가용성 LDAP 연결을 설정하여 장애 발생 가능성을 더욱 줄일 수 있습니다.
자동 또는 수동 SSO 장애 조치 옵션을 제공하기 위해 자체 IDP 설정#
활성 및 대기 인증 옵션 모두에 연결되는 SAML 인증을 위한 사용자 정의 Identity Provider를 생성하여 장애 발생 시 수동 또는 자동으로 전환할 수 있도록 합니다.
이 구성에서는 대기 SSO 옵션이 인증 프로토콜을 약화시키지 않도록 보안을 신중하게 검토해야 합니다.
SSO 장애를 위한 수동 장애 조치 계획 설정#
장애 발생 시 사용자가 조직의 SSO 제공업체에 접근할 수 없는 경우, 지원 링크(System Console 설정에 정의됨)로 연락하라는 오류 메시지가 표시됩니다.
IT가 SSO 장애 문제에 대해 연락을 받으면 System Console을 사용하여 사용자 계정을 SSO에서 email-password로 일시적으로 변경할 수 있으며, 최종 사용자는 SSO 장애가 해결되고 계정이 다시 SSO로 변환될 때까지 비밀번호를 사용하여 계정을 인증할 수 있습니다.
장애가 해결되면 일관성과 보안을 유지하기 위해 모든 사용자를 email-password에서 다시 SSO로 전환하는 것이 중요합니다.