고가용성 클러스터 기반 배포#
![]() Enterprise 플랜 에서 사용 가능
Enterprise 플랜 에서 사용 가능
![]() self-hosted 배포
self-hosted 배포
고가용성 클러스터 기반 배포는 중복 인프라를 사용하여 Mattermost 시스템이 중단 및 하드웨어 장애 중에도 서비스를 유지할 수 있게 합니다.
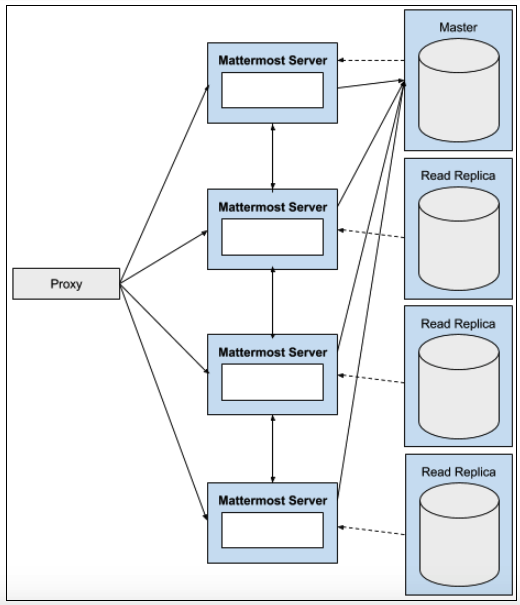
Mattermost의 고가용성은 중복 Mattermost 애플리케이션 서버, 중복 데이터베이스 서버 및 중복 로드 밸런서를 실행하는 것으로 구성됩니다. 이러한 구성 요소 중 하나가 실패하더라도 시스템 운영이 중단되지 않습니다.
Mattermost Enterprise는 다음을 지원합니다:
지연 시간을 최소화하는 클러스터형 Mattermost 서버:
전역 CDN에 정적 자산 저장.
최종 사용자 위치에 더 가깝게 API 통신을 호스팅하기 위해 여러 Mattermost 서버 배포.
재해 복구 시나리오에서 규모 및 장애 전환을 처리하는 데에도 사용할 수 있습니다.
데이터베이스 읽기 복제본은 다음과 같이 사용할 수 있습니다:
활성 데이터베이스 서버의 중복 백업으로 구성.
동시 사용자 수 확장에 사용.
최종 사용자 위치에 더 가깝게 배포하여 지연 시간 감소.
또한 검색 쿼리를 처리하기 위한 검색 복제본도 지원됩니다.
배포 가이드#
Mattermost 서버에서 고가용성 클러스터 기반 배포를 설정하고 유지합니다. 이 문서는 재해 복구 측면에서 데이터베이스 구성에 대해 다루지 않지만, 권장 사항은 자주 묻는 질문(FAQ) 섹션을 참조할 수 있습니다.
인스턴스와 구성이 고가용성 클러스터 기반 배포와 호환되는지 확인하려면 구성 및 호환성 섹션을 검토하세요.
참고
고가용성을 구성하기 전에 Mattermost 데이터베이스와 파일 저장소 위치를 백업하세요. 백업에 대한 자세한 내용은 백업 및 재해 복구 를 참조하세요.
설치 가이드 중 하나를 따라 새 Mattermost 서버를 설정하세요. 이 서버는 구성 파일
config.json의 동일한 복사본을 사용해야 합니다. 각 독립 서버의 개인 IP 주소를 통해 서버가 정상적으로 작동하는지 확인하세요.양쪽 서버의
config.json파일을 수정하여ClusterSettings를 추가하세요. 자세한 내용은 고가용성 클러스터 기반 배포 구성 설정 문서를 참조하세요.양쪽 서버의 구성 파일이 동일한지 확인한 후 클러스터의 각 머신을 재시작하세요.
NGINX 설정을 수정하여 양쪽 서버로 프록시하도록 하세요. 자세한 내용은 프록시 서버 구성 을 참조하세요.
시스템 콘솔 > 환경 > 고가용성 을 열어 클러스터의 각 머신이 녹색 상태 표시등으로 예상대로 통신하는지 확인하세요. 그렇지 않은 경우 로그 파일을 조사하여 추가 정보를 확인하세요.
클러스터에 서버 추가#
Mattermost 데이터베이스와 파일 저장소 위치를 백업하세요. 자세한 내용은 백업 문서를 참조하세요.
새 Mattermost 서버를 설정하세요. 이 서버는 구성 파일
config.json의 동일한 복사본을 사용해야 합니다. 개인 IP 주소로 서버가 정상 작동하는지 확인하세요.NGINX 설정을 수정하여 새 서버를 추가하세요.
시스템 콘솔 > 환경 > 고가용성 을 열어 클러스터의 모든 머신이 녹색 상태 표시등으로 예상대로 통신하는지 확인하세요. 그렇지 않은 경우 로그 파일을 조사하여 추가 정보를 확인하세요.
클러스터에서 서버 제거#
구성 및 호환성#
고가용성을 위한 시스템 구성에 대한 세부 정보.
Mattermost 서버 구성#
구성 설정#
고가용성은
config.json의ClusterSettings섹션에서 구성되며 설정은 시스템 콘솔에서 볼 수 있습니다. 고가용성이 활성화되면 Mattermost 서버의 모든config.json파일이 항상 동일하도록 시스템 콘솔이 읽기 전용 모드로 설정됩니다. 그러나 고가용성 설정을 테스트하고 검증하기 위해ReadOnlyConfig를false로 설정할 수 있으며, 이렇게 하면 시스템 콘솔에서 변경한 내용이 구성 파일에 다시 저장됩니다.
"ClusterSettings": { "Enable": false, "ClusterName": "production", "OverrideHostname": "", "UseIpAddress": true, "ReadOnlyConfig": true, "GossipPort": 8074 }이러한 설정에 대한 자세한 내용은 고가용성 구성 설정 문서를 참조하세요.
프로세스 제한을 8192로, 최대 열린 파일 수를 65536으로 변경하세요.
Mattermost 서버를 호스팅하는 각 머신의
/etc/security/limits.conf를 수정하여 다음 줄을 추가하세요:* soft nofile 65536 * hard nofile 65536 * soft nproc 8192 * hard nproc 8192
WebSocket 연결 수를 늘리세요:
Mattermost 서버를 호스팅하는 각 머신의
/etc/sysctl.conf를 수정하여 다음 줄을 추가하세요:# Extending default port range to handle lots of concurrent connections. net.ipv4.ip_local_port_range = 1025 65000 # Lowering the timeout to faster recycle connections in the FIN-WAIT-2 state. net.ipv4.tcp_fin_timeout = 30 # Reuse TIME-WAIT sockets for new outgoing connections. net.ipv4.tcp_tw_reuse = 1 # Bumping the limit of a listen() backlog. # This is maximum number of established sockets (with an ACK) # waiting to be accepted by the listening process. net.core.somaxconn = 4096 # Increasing the maximum number of connection requests which have # not received an acknowledgment from the client. # This is helpful to handle sudden bursts of new incoming connections. net.ipv4.tcp_max_syn_backlog = 8192 # This is tuned to be 2% of the available memory. vm.min_free_kbytes = 167772 # Disabling slow start helps increasing overall throughput # and performance of persistent single connections. net.ipv4.tcp_slow_start_after_idle = 0 # These show a good performance improvement over defaults. # More info at https://blog.cloudflare.com/http-2-prioritization-with-nginx/ net.ipv4.tcp_congestion_control = bbr net.core.default_qdisc = fq net.ipv4.tcp_notsent_lowat = 16384 # TCP buffer sizes are tuned for 10Gbit/s bandwidth and 0.5ms RTT (as measured intra EC2 cluster). # This gives a BDP (bandwidth-delay-product) of 625000 bytes. net.ipv4.tcp_rmem = 4096 156250 625000 net.ipv4.tcp_wmem = 4096 156250 625000 net.core.rmem_max = 312500 net.core.wmem_max = 312500 net.core.rmem_default = 312500 net.core.wmem_default = 312500 net.ipv4.tcp_mem = 1638400 1638400 1638400
프록시 서버에도 동일하게 적용할 수 있습니다.
클러스터 검색#
비표준(즉, 복잡한) 네트워크 구성을 사용하는 경우 클러스터 노드가 서로를 검색할 수 있도록 호스트명 재정의 설정을 사용해야 할 수 있습니다. 이러한 이유로 구성의 클러스터 설정은 구성 파일 해시에서 제거되며, 이는 고가용성 모드에서 config.json 파일이 약간 다를 수 있음을 의미합니다. 강제 검색이 필요한 경우 config.json 의 각 클러스터 노드에 대해 호스트명 재정의가 다르게 설정되어야 합니다.
UseIpAddress 가 true 로 설정된 경우, 첫 번째 비로컬 IP 주소(비 루프백, 비 로컬유니캐스트, 비 로컬멀티캐스트 네트워크 인터페이스)를 검색하여 IP 주소를 얻으려고 시도합니다. 내장된 go 함수 net.InterfaceAddrs() 를 사용하여 네트워크 인터페이스를 열거합니다. 그렇지 않은 경우 내장된 go 함수 os.Hostname() 를 사용하여 호스트명을 가져오려고 시도합니다.
데이터베이스에 대해 SELECT * FROM ClusterDiscovery 를 실행하여 Hostname 필드가 어떻게 채워졌는지 확인할 수 있습니다. 이 필드는 서버가 클러스터의 다른 노드와 연결을 시도하는 데 사용할 호스트명 또는 IP 주소가 됩니다. url Hostname:Port 와 Hostname:PortGossipPort 에 연결을 시도합니다. 클러스터가 올바르게 통신할 수 있도록 모든 올바른 포트가 열려 있는지 확인해야 합니다. 이러한 포트는 구성의 ClusterSettings 아래에 있습니다.
요약하면, 다음을 사용해야 합니다:
다른 머신에서 첫 번째 비로컬 주소를 볼 수 있는 경우 IP 주소 검색을 사용하세요.
클러스터의 다른 노드에 대해 적절한 검색 가능한 이름이 되도록 운영 체제에서 호스트명을 재정의하세요.
위 단계가 작동하지 않는 경우
config.json에서 호스트명을 재정의하세요. 필요한 경우 이 필드에 IP 주소를 넣을 수 있습니다.config.json은 각 클러스터 노드마다 다를 것입니다.
시간 동기화#
메시지가 올바른 순서로 게시되도록 클러스터의 각 서버에는 Network Time Protocol 데몬 ntpd 가 실행되어야 합니다.
상태#
Mattermost 서버는 수평적 확장을 가능하게 하기 위해 최소한의 상태만 가지도록 설계되었습니다. Mattermost 확장을 위해 고려되는 상태 항목은 다음과 같습니다:
빠른 검증 및 채널 접근을 위한 메모리 내 세션 캐시.
빠른 응답을 위한 메모리 내 온라인/오프라인 캐시.
메모리에 로드되고 저장되는 시스템 구성 파일.
메시지 전송에 사용되는 클라이언트의 WebSocket 연결.
Mattermost 서버가 고가용성으로 구성되면, 서버는 상태를 동기화하기 위해 다른 수신 주소에서 노드 간 통신 프로토콜을 사용합니다. 상태가 변경되면 데이터베이스에 다시 기록되고 노드 간 메시지가 전송되어 다른 서버에 상태 변경을 알립니다. 항목의 실제 상태는 항상 데이터베이스에서 읽을 수 있습니다. Mattermost는 또한 “[User X] is typing”과 같은 실시간 메시지를 위해 WebSocket 메시지를 클러스터의 다른 서버로 전달하는 데 노드 간 통신을 사용합니다.
프록시 서버 구성#
프록시 서버는 Mattermost 서버 클러스터를 외부 세계에 노출합니다. Mattermost 서버는 NGINX, 하드웨어 로드 밸런서 또는 Amazon Elastic Load Balancer와 같은 클라우드 서비스와 같은 프록시 서버와 함께 사용하도록 설계되었습니다.
상태 확인으로 서버를 모니터링하려면 http://10.10.10.2/api/v4/system/ping 을 사용하고 성공을 나타내는 Status 200 응답을 확인하세요. 이 상태 확인 경로를 사용하여 서버를 서비스 중 또는 서비스 중단 으로 표시하세요.
아래에 NGINX의 샘플 구성이 제공됩니다. 이는 10.10.10.2 및 10.10.10.4 의 개인 IP 주소에서 실행되는 두 개의 Mattermost 서버가 있다고 가정합니다.
upstream backend {
server 10.10.10.2:8065;
server 10.10.10.4:8065;
keepalive 256;
}
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=mattermost_cache:50m max_size=16g inactive=60m use_temp_path=off;
server {
listen 80 reuseport;
server_name mattermost.example.com;
location ~ /api/v[0-9]+/(users/)?websocket$ {
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
client_max_body_size 100M;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Frame-Options SAMEORIGIN;
proxy_buffers 256 16k;
proxy_buffer_size 16k;
client_body_timeout 60s;
send_timeout 300s;
lingering_timeout 5s;
proxy_connect_timeout 30s;
proxy_send_timeout 90s;
proxy_read_timeout 90s;
proxy_http_version 1.1;
proxy_pass http://backend;
}
location / {
proxy_set_header Connection "";
client_max_body_size 100M;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Frame-Options SAMEORIGIN;
proxy_buffers 256 16k;
proxy_buffer_size 16k;
client_body_timeout 60s;
send_timeout 300s;
lingering_timeout 5s;
proxy_connect_timeout 30s;
proxy_send_timeout 90s;
proxy_read_timeout 90s;
proxy_http_version 1.1;
proxy_pass http://backend;
proxy_cache mattermost_cache;
proxy_cache_revalidate on;
proxy_cache_min_uses 2;
proxy_cache_use_stale timeout;
proxy_cache_lock on;
}
}
단일 장애 지점을 제한하기 위해 여러 프록시 서버를 사용할 수 있지만, 이는 이 문서의 범위를 벗어납니다.
파일 저장소 구성#
참고
파일 저장소는 NAS 또는 Amazon S3와 같은 서비스를 사용하는 모든 시스템 간에 공유된다고 가정합니다.
"DriverName": "local"이 사용되는 경우"FileSettings":"Directory": "./data/"의 디렉토리는 로컬 디렉토리로 매핑된 NAS 위치여야 합니다. 그렇지 않으면 고가용성이 제대로 작동하지 않고 파일 저장소가 손상될 수 있습니다.파일 저장소로 Amazon S3 또는 MinIO를 사용하는 경우 다른 구성이 필요하지 않습니다.
Mattermost Enterprise의 Compliance Reports 기능을 사용하는 경우, "ComplianceSettings": "Directory": "./data/", 를 모든 시스템 간에 공유하도록 구성해야 합니다. 그렇지 않으면 보고서는 로컬 Mattermost 서버의 시스템 콘솔에서만 사용할 수 있습니다.
로컬 저장소에서 NAS 또는 S3로의 마이그레이션은 이 문서의 범위를 벗어납니다.
데이터베이스 구성#
팁
Mattermost 환경 변수를 사용하여 구성 설정 값을 지정하면 다른 모든 구성 설정보다 항상 우선순위가 높습니다.
AWS 고가용성 RDS 클러스터 배포의 경우, AWS 장애 조치 처리를 활용하기 위해 datasource 구성 설정을 클러스터 수준의 쓰기/읽기 엔드포인트로 지정하세요. AWS는 다른 데이터베이스 노드를 writer 노드로 승격시키는 작업을 처리합니다. Mattermost는 이를 관리할 필요가 없습니다.
데이터베이스 확장을 위해 read replica 기능을 사용하세요. Mattermost 서버는 하나의 마스터 데이터베이스와 하나 이상의 읽기 전용 복제 데이터베이스를 사용하도록 설정할 수 있습니다.
참고
AWS 고가용성 RDS 클러스터 배포의 경우 IP 주소를 하드코딩하지 마세요. 이 구성 설정을 클러스터 수준의 쓰기/읽기 엔드포인트로 지정하세요. 이렇게 하면 AWS가 다른 데이터베이스 노드를 writer 노드로 승격시키는 AWS 장애 조치 처리를 활용할 수 있습니다. Mattermost는 이를 관리할 필요가 없습니다.
대규모 배포에서는 검색 쿼리를 하나 이상의 검색 복제본으로 격리하기 위해 search replicas 기능 사용을 고려하세요. 검색 복제본은 읽기 복제본과 유사하지만 검색 쿼리 처리에만 사용됩니다.
참고
AWS 고가용성 RDS 클러스터 배포의 경우 IP 주소를 하드코딩하지 마세요. 이 구성 설정을 RDS 클러스터 내의 기본 읽기 전용 노드 엔드포인트로 직접 지정하세요. 쓰기 트래픽을 제외하고 AWS/RDS가 처리하는 장애 조치/로드 밸런싱을 우회하고 DataSourceReplicas 배열을 RDS reader 노드 엔드포인트로 채우는 것을 권장합니다. Mattermost는 읽기 전용 연결을 밸런싱하는 자체 방법을 가지고 있으며, 해당 노드가 실패할 경우 해당 쿼리를 DataSource/쓰기+읽기 연결로도 밸런싱할 수 있습니다.
Mattermost는 다음과 같이 쿼리를 분배합니다:
모든 쓰기 요청과 일부 특정 읽기 요청은 마스터로 전송됩니다.
다른 모든 읽기 요청(마스터로 가는 특정 쿼리 제외)은 사용 가능한 읽기 복제본들 사이에 분배됩니다. 읽기 복제본이 없는 경우, 이들은 대신 마스터로 전송됩니다.
검색 요청은 사용 가능한 검색 복제본들 사이에 분배됩니다. 검색 복제본이 없는 경우, 이들은 대신 읽기 복제본으로 전송됩니다(또는 읽기 복제본도 없는 경우 마스터로 전송).
데이터베이스 크기 조정#
데이터베이스 서버 크기 조정에 대한 정보는 엔터프라이즈 배포를 위한 하드웨어 요구사항(다중 서버) 를 참조하세요.
마스터/슬레이브 환경에서는 마스터 시스템이 다운되고 장애 조치가 필요한 경우를 대비해 슬레이브 시스템이 100%의 부하를 처리할 수 있도록 크기를 조정하세요.
다중 데이터베이스 구성 배포#
다중 데이터베이스 Mattermost 서버를 구성하려면:
마스터 데이터베이스 서버의 연결 문자열로
config.json의DataSource설정을 업데이트하세요.["readreplica1", "readreplica2"]형식으로 데이터베이스 읽기 복제본 서버들의 연결 문자열 시리즈로config.json의DataSourceReplicas설정을 업데이트하세요. 각 연결은DriverName설정과도 호환되어야 합니다.
하나의 마스터와 두 개의 읽기 복제본에 대한 SqlSettings 블록 예시입니다:
"SqlSettings": {
"DriverName": "mysql",
"DataSource": "master_user:master_password@tcp(master.server)/mattermost?charset=utf8mb4,utf8\u0026readTimeout=30s\u0026writeTimeout=30s",
"DataSourceReplicas": ["slave_user:slave_password@tcp(replica1.server)/mattermost?charset=utf8mb4,utf8\u0026readTimeout=30s\u0026writeTimeout=30s","slave_user:slave_password@tcp(replica2.server)/mattermost?charset=utf8mb4,utf8\u0026readTimeout=30s\u0026writeTimeout=30s"],
"DataSourceSearchReplicas": [],
"MaxIdleConns": 20,
"MaxOpenConns": 300,
"Trace": false,
"AtRestEncryptKey": "",
"QueryTimeout": 30
}
새 설정은 서버를 중지하고 시작하거나, 다음 섹션에서 설명하는 대로 구성 설정을 로드하여 적용할 수 있습니다.
로드되면 데이터베이스 쓰기 요청은 마스터 데이터베이스로 전송되고 읽기 요청은 목록의 다른 데이터베이스들 사이에 분배됩니다.
활성 서버에 다중 데이터베이스 구성 로드하기#
config.json 에 다중 데이터베이스 구성이 정의된 후, Mattermost 서버를 종료하지 않고도 다음 절차를 사용하여 설정을 적용할 수 있습니다:
시스템 콘솔 > 환경 > 웹 서버 로 이동한 다음,
config.json에서 Mattermost 서버의 구성 설정을 다시 로드하기 위해 디스크에서 구성 다시 로드 를 선택하세요.시스템 콘솔 > 환경 > 데이터베이스 로 이동한 다음, 기존 데이터베이스 연결을 종료하고 다중 데이터베이스 구성에서 새 연결을 설정하기 위해 데이터베이스 연결 재활용 을 선택하세요.
연결 설정이 변경되는 동안 마스터 데이터베이스에 쓰기가 실패하는 짧은 순간이 있을 수 있습니다. 프로세스는 모든 기존 연결이 완료될 때까지 기다린 후 새 연결로 새 요청을 처리하기 시작합니다. 전환 중에 메시지를 보내려고 시도하는 최종 사용자는 Mattermost 서버와의 연결이 끊어진 것과 유사한 경험을 하게 됩니다.
마스터 데이터베이스 수동 장애 조치#
현재 마스터 데이터베이스에서 전환해야 할 필요가 있는 경우(예: 디스크 공간 부족, 유지보수 업데이트 필요 또는 기타 이유로) config.json 의 DataSource 를 업데이트하여 Mattermost 서버가 읽기 복제본 중 하나를 마스터 데이터베이스로 사용하도록 전환할 수 있습니다.
Mattermost 서버를 종료하지 않고 설정을 적용하려면:
시스템 콘솔 > 환경 > 웹 서버 로 이동한 다음,
config.json에서 Mattermost 서버의 구성 설정을 다시 로드하기 위해 디스크에서 구성 다시 로드 를 선택하세요.시스템 콘솔 > 환경 > 데이터베이스 로 이동한 다음, 기존 데이터베이스 연결을 종료하고 다중 데이터베이스 구성에서 새 연결을 설정하기 위해 데이터베이스 연결 재활용 을 선택하세요.
연결 설정이 변경되는 동안 마스터 데이터베이스에 쓰기가 실패하는 짧은 순간이 있을 수 있습니다. 프로세스는 모든 기존 연결이 완료될 때까지 기다린 후 새 연결로 새 요청을 처리하기 시작합니다. 전환 중에 메시지를 보내려고 시도하는 최종 사용자는 Mattermost 서버와의 연결이 끊어진 것과 유사한 경험을 할 수 있습니다.
투명한 장애 조치#
데이터베이스는 기존 데이터베이스 기술을 사용하여 고가용성과 투명한 장애 조치를 위해 구성할 수 있습니다. PostgreSQL 클러스터링이나 Amazon Aurora를 권장합니다. 데이터베이스 투명 장애 조치는 이 문서의 범위를 벗어납니다.
PostgreSQL 권장 구성 설정#
Postgres 서비스에 대해 Mattermost 서버에서 다음과 같은 구성 최적화를 권장합니다. 이러한 구성은 AWS Aurora r5.xlarge 인스턴스에서 테스트되었습니다. 더 높은 사양의 서버가 필요한 일반적인 최적화도 언급되어 있습니다.
Postgres 주 또는 Writer 노드 구성
# If the instance is lower capacity than r5.xlarge, then set it to a lower number.
# Also tune the "MaxOpenConns" setting under the "SqlSettings" of the Mattermost app accordingly.
# Note that "MaxOpenConns" on Mattermost is per data source name.
max_connections = 1024
# Set it to 1.1, unless the DB is using spinning disks.
random_page_cost = 1.1
# This should be 32MB if using read replicas, or 16MB if using a single PostgreSQL instance.
# If the instance is of a lower capacity than r5.xlarge, then set it to a lower number.
work_mem = 32MB
# Set both of the below settings to 65% of total memory. For a 32 GB instance, it should be 21 GB.
# If on a smaller server, set this to 20% or less total RAM.
# ex: 512MB would work for a 4GB RAM server
effective_cache_size = 21GB
shared_buffers = 21GB
# If you are using pgbouncer, or any similar connection pooling proxy,
# in front of your DB, then apply the keepalive settings to the proxy instead,
# and revert the keepalive settings for the DB back to defaults.
tcp_keepalives_idle = 5
tcp_keepalives_interval = 1
tcp_keepalives_count = 5
# 1GB (reduce this to 512MB if your server has less than 32GB of RAM)
maintenance_work_mem = 512MB
autovacuum_max_workers = 4
autovacuum_vacuum_cost_limit = 500
# If you have more than 32 CPUs on your database server, please set the following options to utilize more CPU for your server:
max_worker_processes = 12
max_parallel_workers_per_gather = 4
max_parallel_workers = 12
max_parallel_maintenance_workers = 4
Postgres 복제본 노드 구성
위의 모든 설정을 읽기 복제본에 복사하고 아래 항목만 수정하거나 추가하세요.
# If the instance is lower capacity than r5.xlarge, then set it to a lower number.
# Also tune the "MaxOpenConns" setting under the "SqlSettings" of the Mattermost app accordingly.
# Note that "MaxOpenConns" on Mattermost is per data source name.
max_connections = 1024
# This setting should be 16MB on read nodes, and 32MB on writer nodes
work_mem = 16MB
# The below settings allow the reader to return query results even when the primary has a write process running, a query conflict.
# This is set to on because of the high volume of write traffic that can prevent the reader from returning query results within the timeout.
# https://www.postgresql.org/docs/current/hot-standby.html#HOT-STANDBY-CONFLICT
hot_standby = on
hot_standby_feedback = on
vacuuming에 대한 참고 사항
Postgres 데이터베이스의 성능은 vacuuming 및 analyzing 에 특히 민감합니다. 테이블이 얼마나 자주 vacuum되는지 확인하는 좋은 방법은 다음 쿼리를 사용하는 것입니다:
SELECT relname, n_tup_ins as inserts,n_tup_upd as updates,n_tup_del as deletes, n_live_tup as live_tuples, n_dead_tup as dead_tuples, n_mod_since_analyze, last_autovacuum, last_autoanalyze, autovacuum_count, autoanalyze_count FROM pg_stat_user_tables order by dead_tuples desc LIMIT 10;
이 쿼리의 출력은 어떤 테이블이 가장 많은 dead tuple을 누적했는지 나타냅니다. last_autovacuum 및 last_autoanalyze 열을 확인하여 마지막 autovacuum 또는 autoanalyze가 실행된 시점을 볼 수도 있습니다.
이러한 값에 따라 autovacuum 또는 autoanalyze 임계값에 대한 테이블별 값을 조정할 수 있습니다. 예를 들어, 테이블에 50,000개 이상의 dead tuple이 있고 지난 6개월 동안 vacuum이나 analyze가 실행되지 않았다면, 더 적극적인 vacuuming이 도움이 될 가능성이 높습니다. 이 경우 다음을 실행하여 테이블을 조정할 수 있습니다:
ALTER TABLE <table> SET (
autovacuum_vacuum_scale_factor = 0.1, -- default is 0.2
autovacuum_analyze_scale_factor = 0.05, -- default is 0.1
autovacuum_vacuum_cost_limit = 1000 -- default is 200
);
필요에 따라 다른 값을 자유롭게 선택하세요. Postgres가 vacuuming 실행 시점을 계산하는 방법에 대한 자세한 내용은 https://www.postgresql.org/docs/current/routine-vacuuming.html#AUTOVACUUM 를 참조하세요. 초기 SQL 쿼리를 수시로 다시 실행하고 그에 따라 값을 조정하세요.
리더 선출#
클러스터 리더 선출 프로세스는 LDAP 동기화와 같은 예약된 작업을 다중 노드 클러스터 환경의 단일 노드에서 실행하도록 할당합니다.
이 프로세스는 널리 사용되는 bully 리더 선출 알고리즘 을 기반으로 하며, 실패하지 않은 프로세스 중에서 가장 낮은 노드 ID 번호를 가진 프로세스가 리더로 선택됩니다.
작업 서버#
Mattermost는 작업 서버 를 통해 주기적 작업을 실행합니다. 이러한 작업에는 다음이 포함됩니다:
LDAP 동기화
데이터 보존
규정 준수 내보내기
Elasticsearch 인덱싱
클러스터의 모든 앱 및 작업 서버에 대해 config.json 에서 JobSettings.RunScheduler 를 true 로 설정했는지 확인하세요. 그러면 클러스터 리더가 반복 작업 스케줄링을 담당하게 됩니다.
참고
이 설정을 기본값인 true 에서 변경하지 않는 것을 강력히 권장합니다. 이는 ClusterLeader 가 스케줄러를 실행할 수 없게 하기 때문입니다. 결과적으로 LDAP 동기화, 규정 준수 내보내기, 데이터 보존과 같은 반복 작업이 더 이상 스케줄링되지 않습니다.
이전 Mattermost 서버 버전과 이 문서에서는 RunScheduler: false 로 작업 서버를 실행하도록 지시했습니다. 클러스터 설계가 발전하여 더 이상 그렇지 않습니다.
플러그인 및 고가용성#
플러그인을 설치하거나 업그레이드하면 클러스터의 모든 서버에 자동으로 전파됩니다. 파일 저장소는 NAS나 Amazon S3와 같은 서비스를 사용하여 모든 서버 간에 공유되는 것으로 가정됩니다.
"DriverName": "local" 를 사용하는 경우 "FileSettings": "Directory": "./data/" 의 디렉토리는 로컬 디렉토리로 매핑된 NAS 위치여야 합니다. 그렇지 않으면 고가용성이 제대로 작동하지 않고 파일 저장소가 손상될 수 있습니다.
v5.14에서 플러그인을 재설치하면 이전의 Enabled 또는 Disabled 상태가 유지됩니다. v5.15부터는 재설치된 플러그인의 초기 상태가 Disabled 입니다.
CLI 및 고가용성#
CLI는 단일 노드에서 실행되며, 이는 고가용성 환경 이 클러스터의 모든 노드에서 작업을 수행하는 데 사용하는 메커니즘을 우회합니다. 결과적으로 고가용성 환경에서 CLI 명령 을 실행할 때 사용자 업데이트 및 삭제나 구성 설정 변경과 같은 작업에는 서버 재시작이 필요합니다.
서버 재시작이 필요하지 않기 때문에 고가용성 환경에서는 mmctl 사용을 권장합니다. 이러한 변경은 API 계층을 통해 이루어지므로 변경 요청을 받는 노드가 클러스터의 다른 모든 노드에 알립니다.
업그레이드 가이드#
업데이트는 버그나 성능 문제를 해결하는 Mattermost 서버의 점진적인 변경입니다. 업그레이드는 서버에 새로운 기능이나 개선된 기능을 추가합니다.
연속 운영 중 구성 변경 업데이트#
대부분의 구성 업데이트에는 서비스 중단이 필요하지 않습니다. 서비스 중단이 필요한 업그레이드에 대한 자세한 내용은 아래 섹션을 참조하세요. 낮은 부하 기간에 업데이트를 적용할 수 있지만, 고가용성 클러스터 기반 배포가 올바르게 크기 조정된 경우 언제든지 수행할 수 있습니다. 시스템 가동 중단 시간은 짧으며 클러스터의 Mattermost 서버 수에 따라 달라집니다. 기계를 재시작하는 것이 아니라 Mattermost 서버 애플리케이션만 재시작한다는 점에 유의하세요. Mattermost 서버 재시작은 일반적으로 약 5초가 소요됩니다.
참고
시스템 콘솔을 통해 구성 설정을 수정하지 마세요. 그렇지 않으면 고가용성 클러스터 기반 배포에서 서로 다른 config.json 파일을 가진 두 개의 서버가 있어 사용자가 다른 앱 서버에 연결할 때마다 새로고침이 발생합니다.
기존
config.json파일의 백업을 만드세요.Mattermost 서버 중 하나에서
config.json에 구성 변경을 적용하고 파일을 저장하세요. 아직 파일을 다시 로드하지 마세요.config.json파일을 다른 서버에 복사하세요.한 서버를 제외한 모든 서버에서 Mattermost를 종료하세요.
여전히 실행 중인 서버에서 구성 파일을 다시 로드하세요. 시스템 콘솔 > 환경 > 웹 서버 로 이동한 다음 디스크에서 구성 다시 로드 를 선택하세요.
다른 서버를 시작하세요.
연속 운영 중 서버 버전 업데이트#
Mattermost 서버의 보안 패치 도트 릴리스에는 서비스 중단이 필요하지 않습니다. 예상 부하가 한 서버가 업데이트 중에 시스템의 전체 부하를 감당할 수 있을 정도로 작은 기간에 업데이트를 적용할 수 있습니다.
참고
롤링 업그레이드 수행 시 Mattermost는 서버 버전 간 하나의 마이너 버전 차이를 지원합니다(예: v5.27.1 + v5.27.2 또는 v5.26.4 + v5.27.1은 지원되지만, v5.25.5 + v5.27.0은 지원되지 않음). 클러스터에서 두 개의 다른 버전의 Mattermost를 실행하는 것은 업그레이드 시나리오 외에는 수행하지 않아야 합니다.
재시작할 때는 머신을 재시작하는 것이 아니라 Mattermost 서버 애플리케이션만 재시작하는 것입니다. Mattermost 서버 재시작은 일반적으로 약 5초가 소요됩니다.
Mattermost 서버 업그레이드 의 Enterprise Edition 업그레이드 섹션에서 업그레이드 절차를 검토하세요.
기존
config.json파일의 백업을 만드세요.프록시를 설정하여 모든 새 요청을 단일 서버로 이동하세요. NGINX를 사용하고
/etc/nginx/sites-available/mattermost에 업스트림 백엔드 섹션이 구성되어 있다면, 먼저 업데이트하려는 서버를 제외한 모든 서버를 주석 처리하고 NGINX를 다시 로드하세요.먼저 업데이트하려는 서버를 제외한 각 서버에서 Mattermost를 종료하세요.
종료된 각 Mattermost 인스턴스를 업데이트하세요.
각 서버에서 새
config.json파일을 백업한 복사본으로 교체하세요.Mattermost 서버를 시작하세요.
계속 실행 중이던 서버에 대해 업데이트 절차를 반복하세요.
서비스 중단이 필요한 서버 업그레이드#
데이터베이스 스키마 변경이 포함된 업그레이드나 config.json 변경으로 인해 서버 재시작이 필요한 경우(예: 다음과 같은 변경 시)에는 서비스 중단이 필요합니다:
기본 서버 언어
속도 제한
웹서버 모드
데이터베이스
고가용성
업그레이드에 데이터베이스 스키마 변경이 포함된 경우, 데이터베이스는 시작하는 첫 번째 서버에 의해 업그레이드됩니다.
부하가 적은 기간에 업그레이드를 적용하세요. 시스템 가동 중단 시간은 짧으며 클러스터의 Mattermost 서버 수에 따라 달라집니다. 머신을 재시작하는 것이 아니라 Mattermost 서버 애플리케이션만 재시작한다는 점에 유의하세요.
Mattermost 서버 업그레이드 의 Enterprise Edition 업그레이드 섹션에서 업그레이드 절차를 검토하세요.
기존
config.json파일의 백업을 만드세요.NGINX를 중지하세요.
각 Mattermost 인스턴스를 업그레이드하세요.
각 서버에서 새
config.json파일을 백업한 복사본으로 교체하세요.Mattermost 서버 중 하나를 시작하세요.
서버가 실행되면 다른 서버들을 시작하세요.
NGINX를 재시작하세요.
모든 클러스터 노드는 단일 프로토콜을 사용해야 합니다#
모든 클러스터 트래픽은 gossip 프로토콜을 사용합니다. Gossip 클러스터링은 더 이상 비활성화할 수 없습니다.
고가용성 클러스터 기반 배포를 업그레이드할 때, 하나의 노드가 gossip 프로토콜을 사용하지 않으면 클러스터의 다른 노드를 업그레이드할 수 없습니다. 이러한 유형의 업그레이드를 완료하려면 gossip을 사용해야 합니다. 또는 모든 노드를 종료하고 업그레이드 후 개별적으로 다시 시작할 수 있습니다.
지속적인 운영을 위한 요구사항#
서버 업데이트 및 서버 업그레이드 중을 포함하여 항상 지속적인 운영을 가능하게 하려면, 중복 구성 요소가 적절한 크기로 조정되어 있는지 확인하고 시스템의 각 구성 요소를 업데이트하는 올바른 순서를 따라야 합니다.
- 예상 규모의 중복성
하나의 구성 요소가 실패할 경우, 나머지 애플리케이션 서버, 데이터베이스 서버 및 로드 밸런서는 시스템의 전체 부하를 처리할 수 있도록 크기가 조정되고 구성되어야 합니다. 이 요구사항이 충족되지 않으면 하나의 구성 요소 중단이 나머지 구성 요소의 과부하를 초래하여 전체 시스템 중단을 일으킬 수 있습니다.
- 지속적인 운영을 위한 업데이트 순서
시스템 구성 요소를 올바른 순서로 업데이트하는 한, 서비스 중단 없이 대부분의 구성 변경 및 dot 릴리스 보안 업데이트를 적용할 수 있습니다. 이에 대한 지침은 upgrade guide 를 참조하세요.
예외: 서버 재시작이 필요한 구성 설정 변경 및 데이터베이스 스키마 변경이 포함된 서버 버전 업그레이드는 짧은 가동 중단 시간이 필요합니다. 서버 재시작의 가동 중단 시간은 약 5초입니다. 데이터베이스 스키마 업데이트의 경우 가동 중단 시간은 최대 30초까지 걸릴 수 있습니다.
중요
Mattermost는 여러 데이터 센터에 걸친 고가용성 배포를 지원하지 않습니다. 고가용성 클러스터의 모든 노드는 적절한 기능과 성능을 보장하기 위해 동일한 데이터 센터 내에 있어야 합니다.
자주 묻는 질문(FAQ)#
Mattermost는 다중 리전 고가용성 클러스터 기반 배포를 지원하나요?#
네. 공식적으로 테스트되지 않았지만, 예를 들어 AWS 리전에 걸쳐 클러스터를 설정할 수 있으며 문제 없이 작동해야 합니다.
Mattermost는 데이터베이스의 재해 복구에 대해 어떤 것을 권장하나요?#
고가용성 구성으로 Mattermost를 배포할 때, Mattermost와 데이터베이스 사이에 데이터베이스 로드 밸런서를 사용하는 것을 권장합니다. 배포에 따라 이에 대한 고려가 더 많거나 적을 수 있습니다.
예를 들어, Amazon Aurora와 함께 AWS에 Mattermost를 배포하는 경우 여러 가용 영역을 활용하는 것을 권장합니다. 자체 클러스터에 Mattermost를 배포하는 경우 기존 아키텍처에 가장 적합한 솔루션을 위해 IT 팀과 상담하세요.
연결된 웹소켓의 호스트명을 찾는 방법은 무엇인가요?#
Mattermost v10.4부터 자체 호스팅 배포를 실행하는 Enterprise 고객은 Product 메뉴  로 이동하여 About Mattermost 를 선택하면 Mattermost를 실행 중인 클러스터의 노드 호스트명을 볼 수 있습니다.
로 이동하여 About Mattermost 를 선택하면 Mattermost를 실행 중인 클러스터의 노드 호스트명을 볼 수 있습니다.
문제 해결#
고가용성 문제 해결 데이터 캡처#
고가용성 구성으로 Mattermost를 배포할 때, Prometheus와 Grafana 메트릭뿐만 아니라 클러스터 서버 로그를 가능한 한 오래 보관하는 것을 권장합니다 - 최소 2주 이상.
분석 및 문제 해결 목적으로 이 데이터를 Mattermost에 제공하도록 요청받을 수 있습니다.
참고
서버 로그 파일이 생성되고 있는지 확인하세요. Mattermost 로그 작업에 대한 자세한 내용은 여기 에서 찾을 수 있습니다.
문제를 조사하고 재현할 때는 시스템 콘솔 > 환경 > 로깅 을 열고 파일 로그 레벨 을 DEBUG 로 설정하여 더 완전한 로그를 얻는 것을 권장합니다. 디스크 공간을 절약하기 위해 문제 해결 후 INFO 로 되돌리는 것을 잊지 마세요.
각 서버는 자체 서버 로그 파일을 가지므로, 고가용성 클러스터 기반 배포의 모든 서버에 대한 서버 로그를 제공해야 합니다.
빨간색 서버 상태#
고가용성 모드가 활성화되면 시스템 콘솔은 서버가 클러스터와 올바르게 통신하는지 여부를 나타내는 빨간색 또는 녹색으로 서버 상태를 표시합니다. 서버는 클러스터 내의 다른 머신에 ping을 보내기 위해 노드 간 통신을 사용하며, ping이 설정되면 서버는 서버 버전 및 구성 파일과 같은 정보를 교환합니다.
서버 상태가 빨간색으로 표시되는 이유는 다음과 같습니다:
구성 파일 불일치: Mattermost는 여전히 노드 간 통신을 시도하지만, 고가용성 모드 기능이 제대로 작동하려면 동일한 구성 파일이 필요하므로 시스템 콘솔은 서버에 대해 빨간색 상태를 표시합니다.
서버 버전 불일치: Mattermost는 여전히 노드 간 통신을 시도하지만, 고가용성 모드 기능은 클러스터의 각 서버에 동일한 버전의 Mattermost가 설치되어 있다고 가정하므로 시스템 콘솔은 서버에 대해 빨간색 상태를 표시합니다. 모든 서버에서 Mattermost 최신 버전 을 사용하는 것이 좋습니다. 업그레이드가 필요한 서버는 Mattermost 서버 업그레이드 의 업그레이드 절차를 따르세요.
서버 다운: 노드 간 통신이 메시지 전송에 실패하면 15초 후에 다시 시도합니다. 두 번째 시도도 실패하면 서버가 다운된 것으로 간주됩니다. 오류 메시지가 로그에 기록되고 시스템 콘솔은 해당 서버에 대해 빨간색 상태를 표시합니다. 노드 간 통신은 15초 간격으로 다운된 서버에 계속 ping을 보냅니다. 서버가 다시 시작되면 새로운 메시지가 전송됩니다.
WebSocket 연결 끊김#
클라이언트 WebSocket이 연결 끊김을 수신하면 백오프와 함께 3초마다 자동으로 연결을 다시 설정하려고 시도합니다. 연결이 설정되면 클라이언트는 연결이 끊어진 동안 전송된 모든 메시지를 수신하려고 시도합니다.
앱이 지속적으로 새로고침됨#
시스템 콘솔을 통해 구성 설정이 수정되면 사용자가 다른 앱 서버에 연결할 때마다 클라이언트가 새로고침됩니다. 이는 고가용성 클러스터 기반 배포에서 서버가 서로 다른 config.json 파일을 가지고 있기 때문에 발생합니다.
config.json 을 통해 직접 구성 설정을 수정하세요 다음 단계를 따르세요.
새로고침 후까지 메시지가 게시되지 않음#
고가용성 모드에서 실행할 때는 모든 Mattermost 애플리케이션 서버가 동일한 버전의 Mattermost를 실행하고 있는지 확인하세요. 서로 다른 버전을 실행 중인 경우, 낮은 버전의 앱 서버가 요청을 처리할 수 없고 프론트엔드 애플리케이션이 새로고침되어 유효한 Mattermost 버전의 서버로 전송될 때까지 요청이 전송되지 않는 상태가 될 수 있습니다. 주의해야 할 증상으로는 요청이 무작위로 실패하거나 단일 애플리케이션 서버의 goroutine과 API 오류가 급격히 증가하는 것이 있습니다.